Dimension-wise Entropy Modulation
DEM learns an action-wise variance budget, suppressing noise on precision-critical joints while preserving exploration capacity on redundant or task-irrelevant dimensions.
Maximum Entropy RL for High-Dimensional Humanoid Control
Unlocking stochastic policies in high-dimensional humanoid control with dimension-wise entropy modulation and a continuous distributional critic.
Overview
Modern humanoid RL is dominated by deterministic policy gradients because they remain stable in massively parallel simulators. FastDSAC shows that maximum entropy RL can compete in this regime when exploration and value estimation are redesigned for large action spaces.
The method keeps the efficient FastTD3-style training recipe, but replaces uniform action noise with a learned exploration budget and models returns with a continuous Gaussian critic.
Method
DEM learns an action-wise variance budget, suppressing noise on precision-critical joints while preserving exploration capacity on redundant or task-irrelevant dimensions.
A Gaussian return critic avoids fixed C51 supports and quantization artifacts, improving value fidelity across tasks with different reward scales.

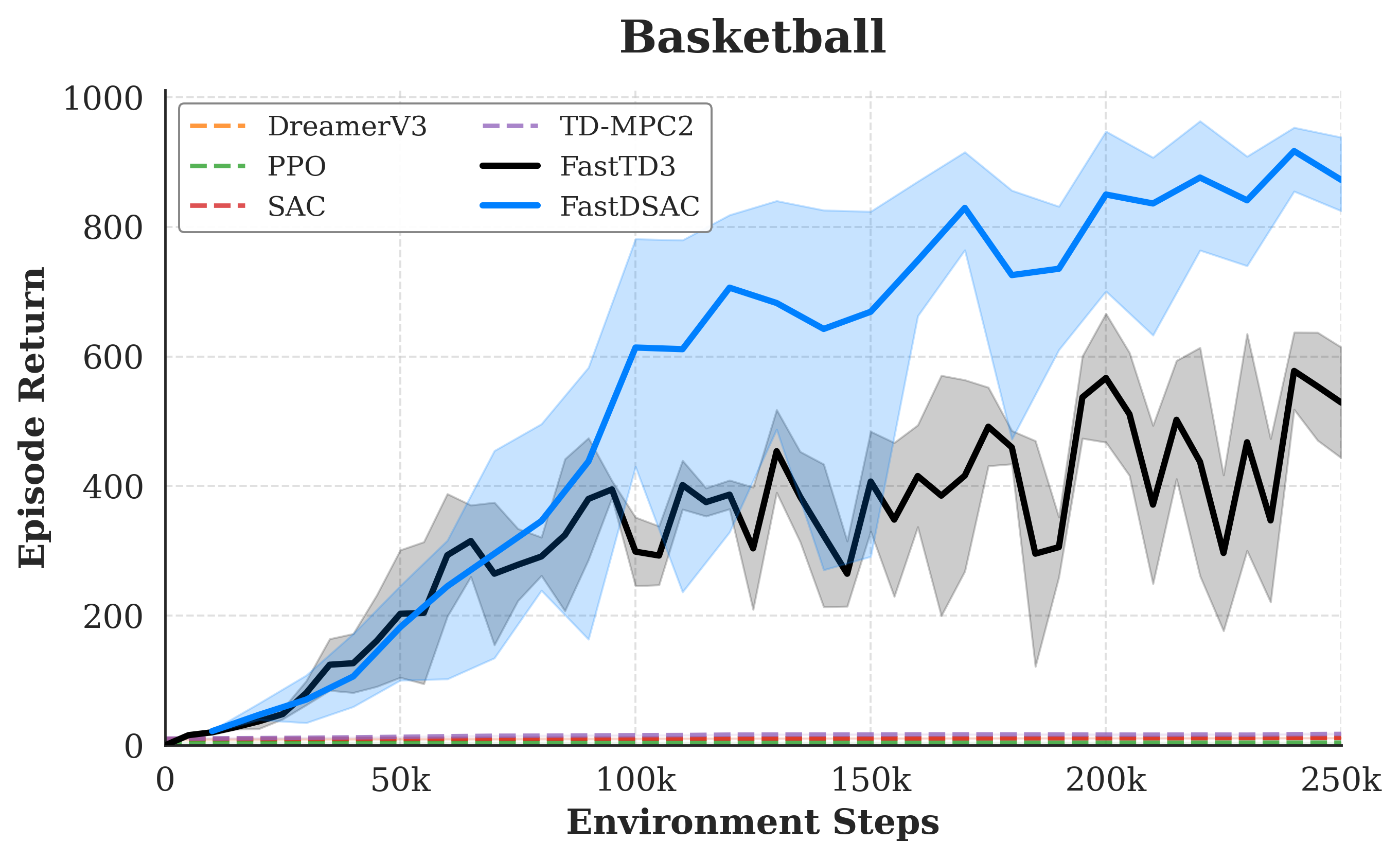
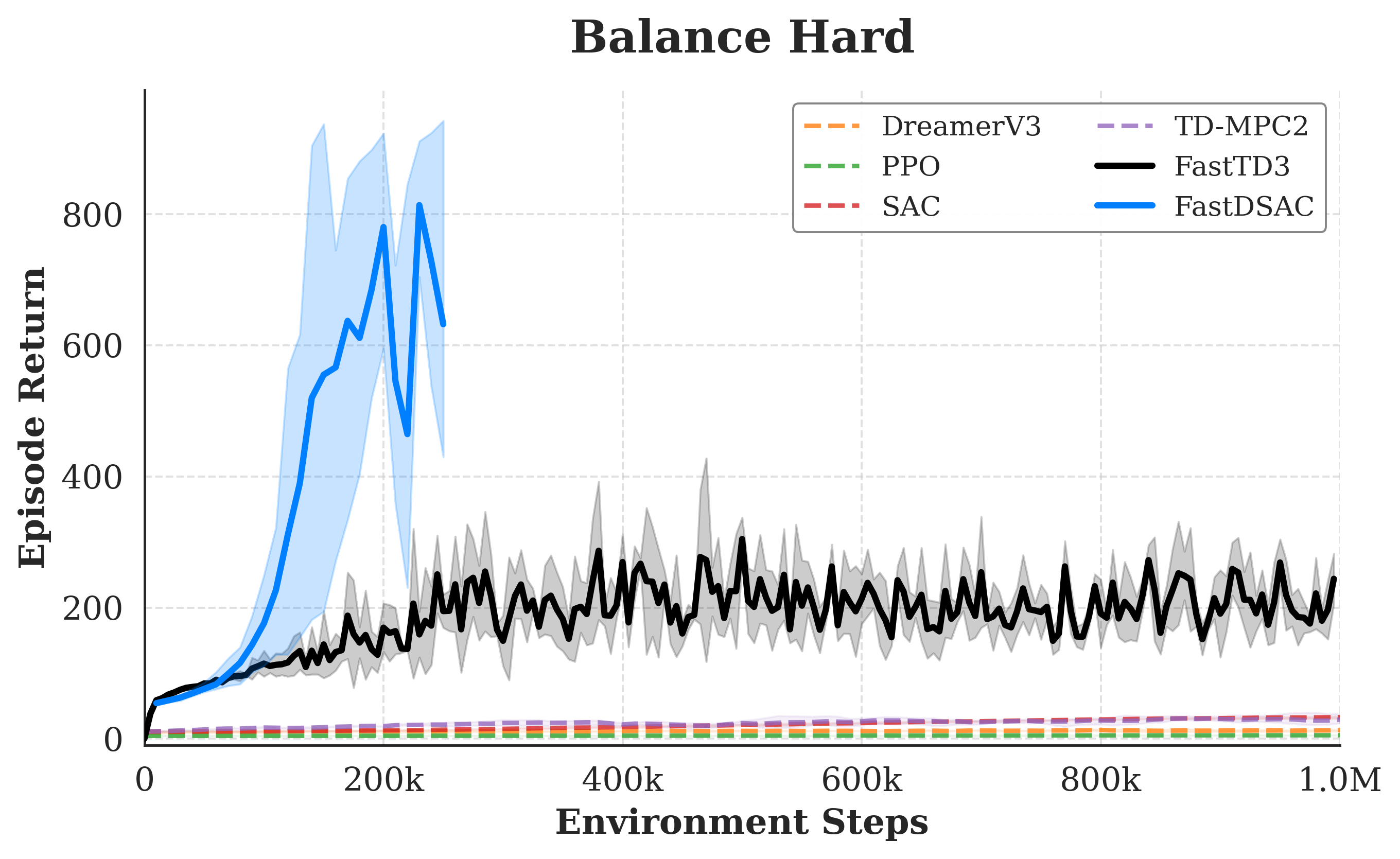
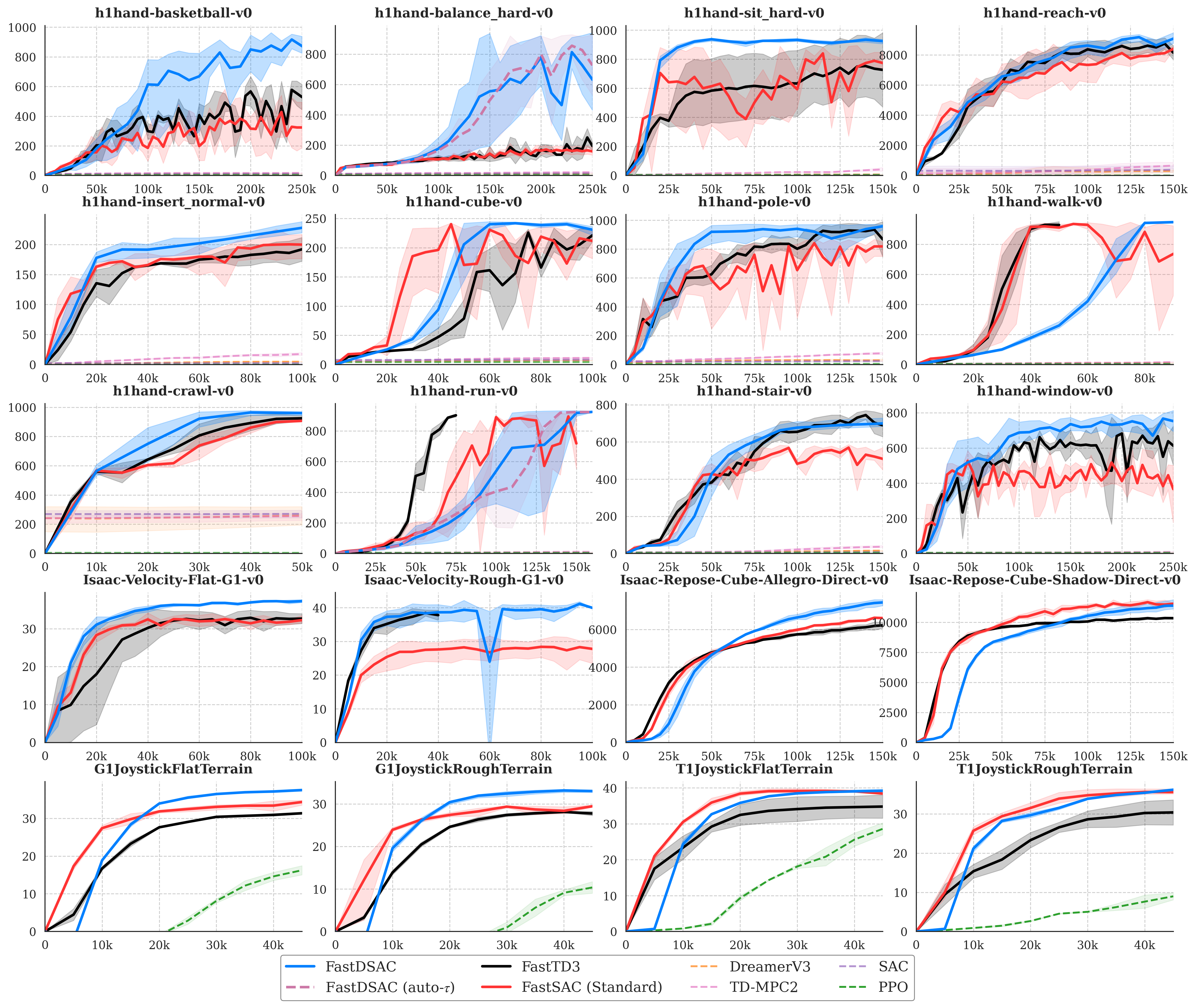
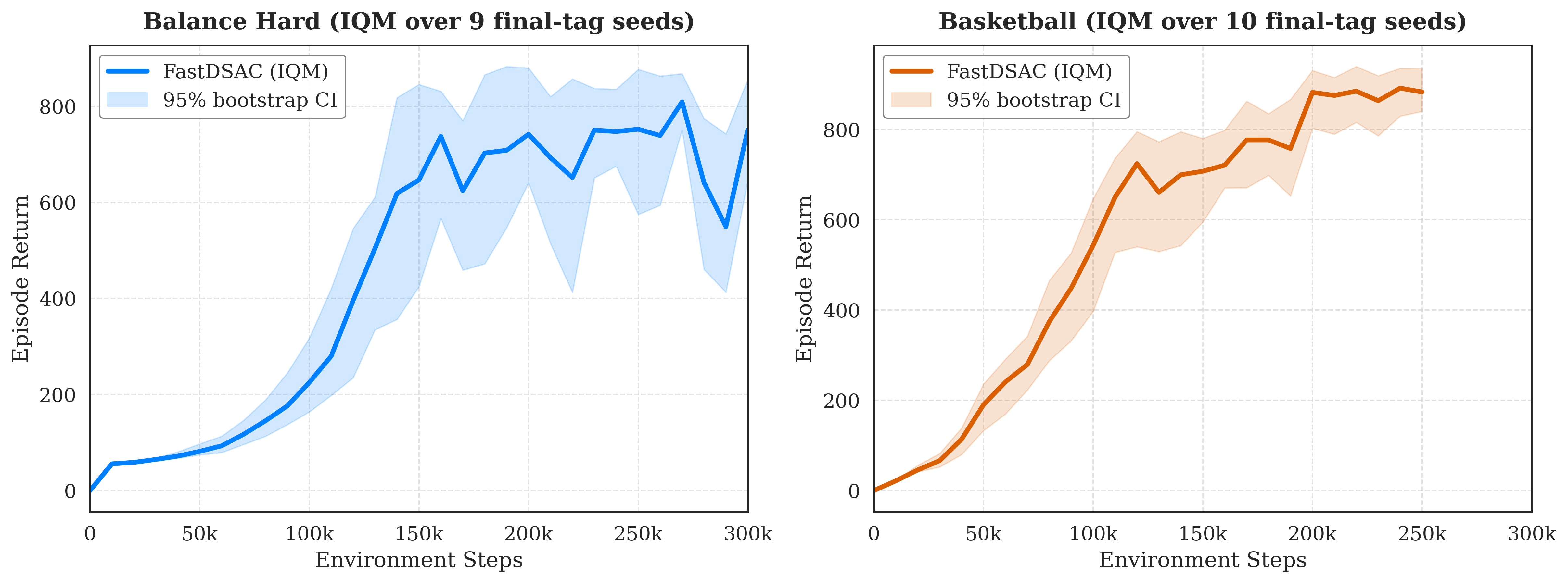
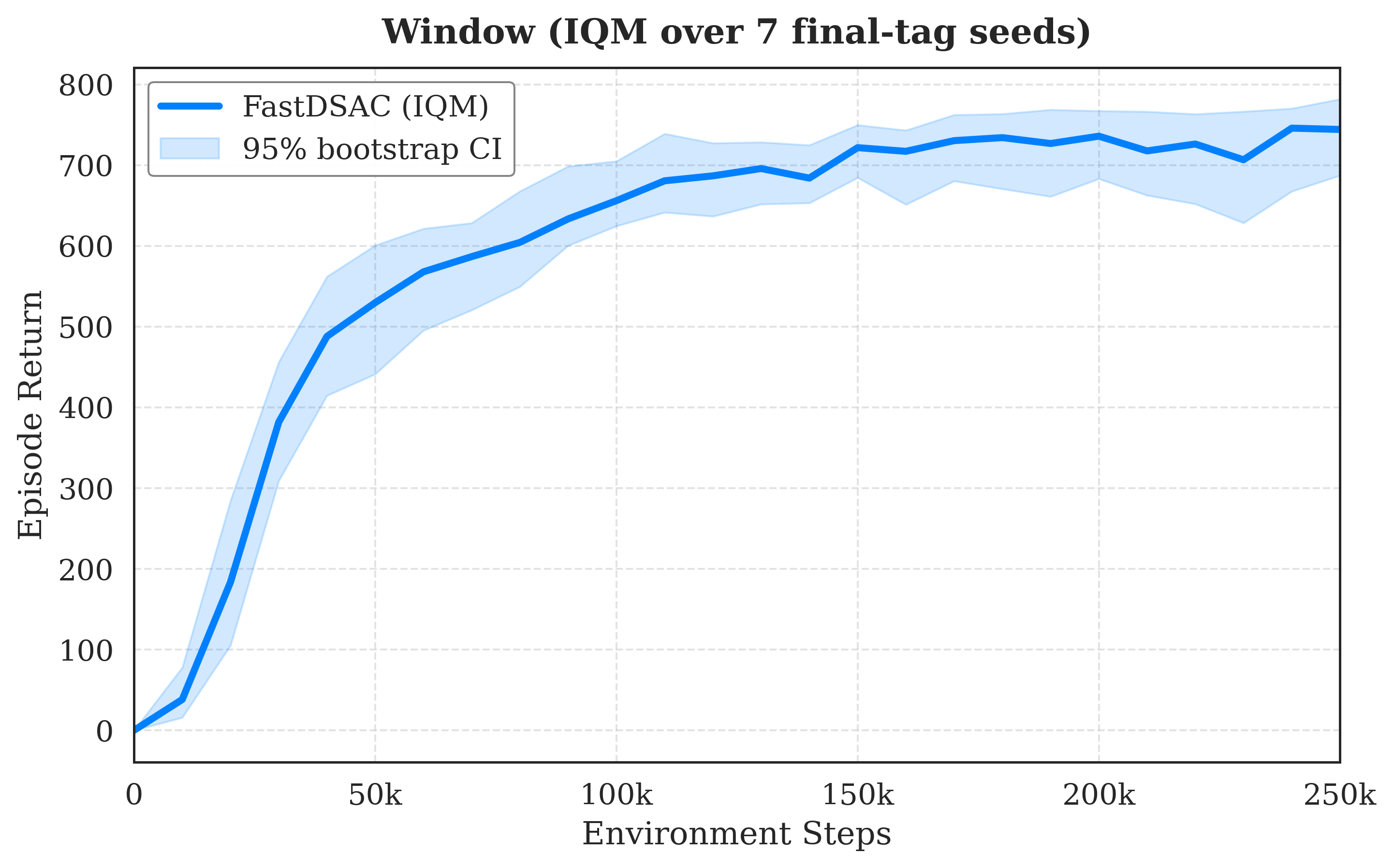
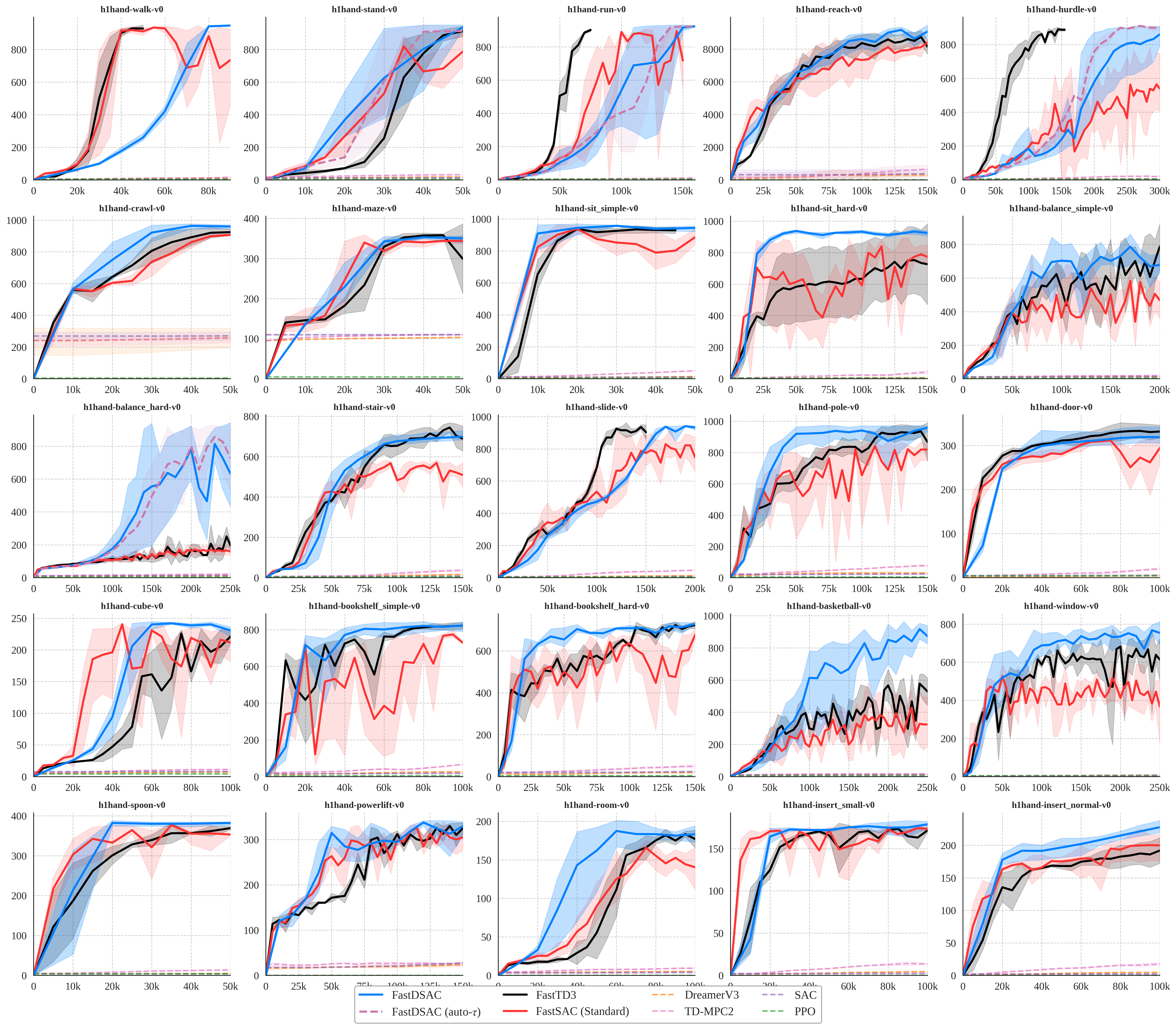
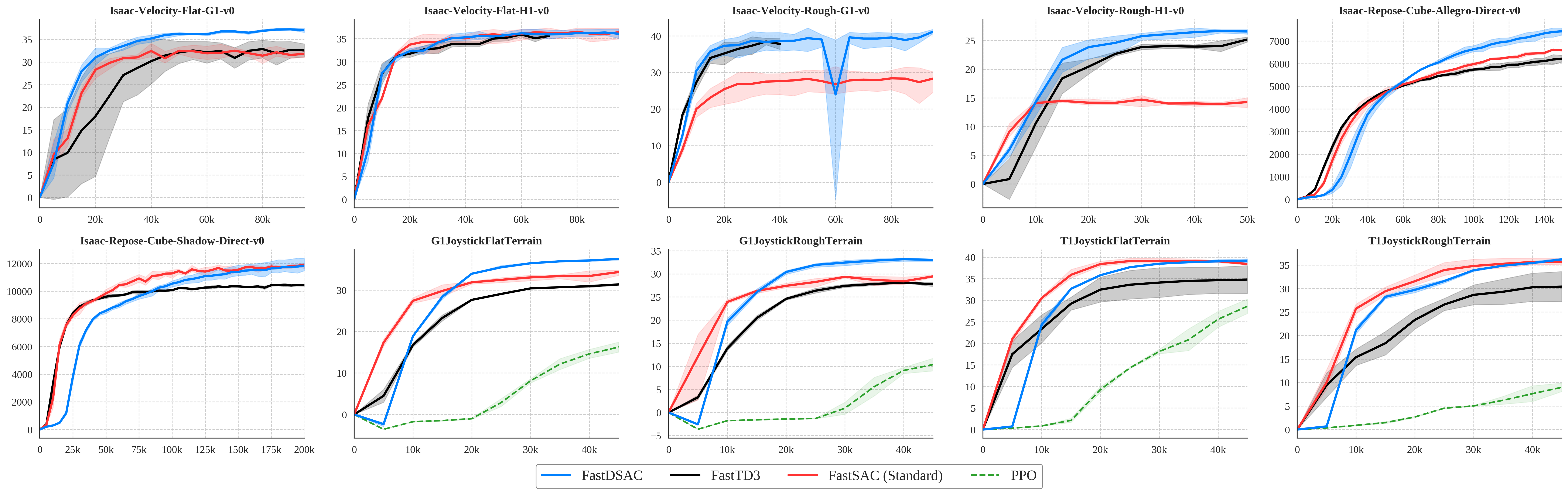
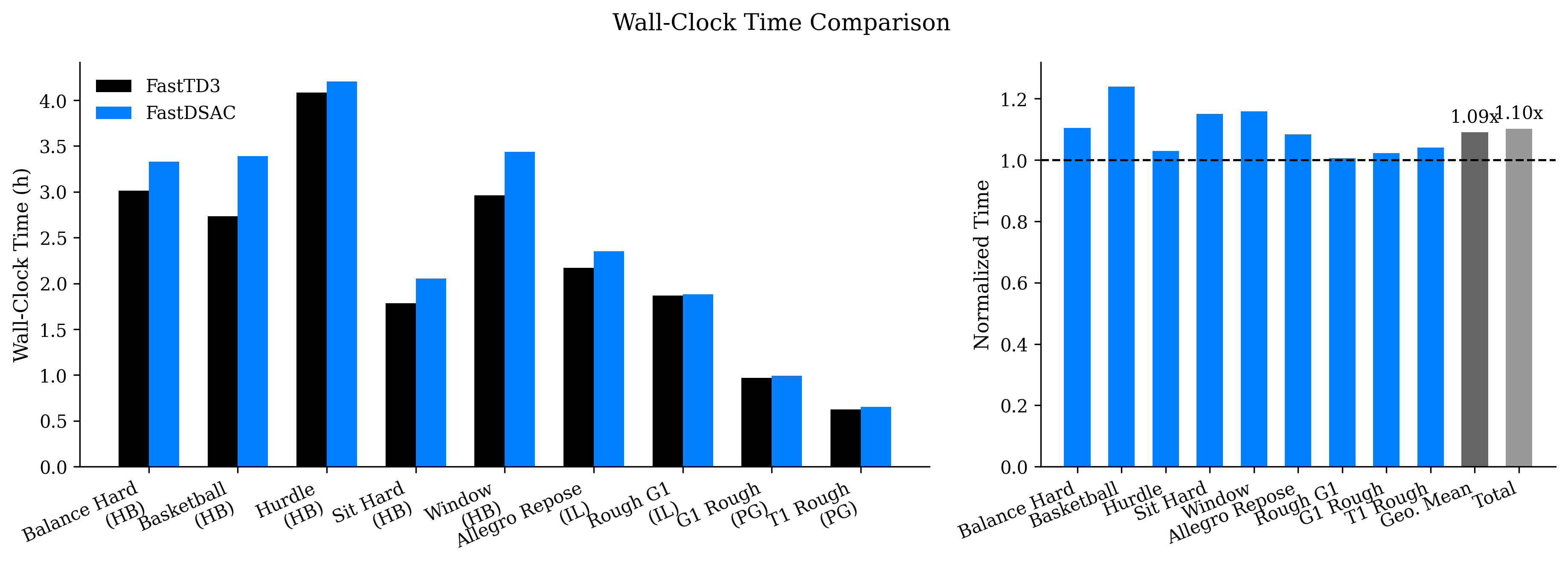
Results
Main benchmark panels come first. Multi-seed IQM curves with 95% confidence intervals then provide statistical evidence for the hardest standout tasks.
Demos






Citation
@article{xue2026fastdsac,
title = {FastDSAC: Unlocking the Potential of Maximum Entropy RL in High-Dimensional Humanoid Control},
author = {Xue, Jun and Wang, Junze and Wang, Shanze and Zhang, Xinming and Chen, Yanjun and Zhang, Wei},
journal = {arXiv preprint arXiv:2603.12612},
year = {2026},
doi = {10.48550/arXiv.2603.12612},
url = {https://arxiv.org/abs/2603.12612}
}